2018.09.30更新: 在VOT2015部分补充R score的定义
上一篇博文简单介绍了vot-toolkit的使用方法。当然,那只是操作层面的东西,更重要的是我们通过这个工具得到的各种图表以及图表中的数据。而想要完整地评价一个tracker的性能,其指标必然不会过于简单,所以就有了这篇文章。我想通过梳理VOT2013到VOT2016评价指标的变化,呈现一个更加清晰的思路,让各位对VOT的认识更加深刻。
这篇文章先对VOT进行总体概述,再按照时间顺序分别叙述,循序渐进。
首先简单介绍VOT是什么:
VOT (Visual Object Tracking) 是一个针对单目标跟踪的测试平台,从2013年发展到现在,已经成为单目标跟踪领域主流的三大平台之一(另外两个是OTB、ALOV)。
作为一个测试平台,VOT有着自己的评价指标,并且指标在发展过程中不断完善,每年VOT都会有新的评价指标出现,或是对现有的评价体系进行改进。
1. VOT评价指标的核心
VOT认为,对一个tracker的评价应该具备三个要素: (1). 评价方法(Performance measures); (2). 数据集(Datasets); (3). 评价系统(Evaluation systems)
其中,第一点和第三点是不同的,评价方法侧重于这个评价体系的思路,而评价系统侧重于具体操作,即如何搭建一个可用的测试平台。接下来,对这三点具体阐述:
(1). 评价方法:VOT认为,仅仅根据测试出的数据对trackers进行排名不够精准,对于两个或多个tracker,它们通过测试得出的数据可能会不完全相等,但是在实际情况下它们的表现是相同(performing equally well)的,即实验数据不等同于实际表现,为了更加精准地测出tracker的实际表现,VOT认为应该通过一种算法判定:什么情况下tracker的表现可以视作相同,这被称作tracker equivalence;
(2). 数据集:VOT认为,数据集只有规模大是完全不行的,一个可靠的数据集应该测试出tracker在不同条件下的表现,例如部分遮挡(partial occlusion)、光照变化(illumination changes)等。由此,VOT提出,应该对每一个序列都标注出该序列的视觉属性(visual attributes),以对应上述的不同条件,VOT2013共提出了六种视觉属性:
- 相机移动(camera motion,即抖动模糊)
- 光照变化(illumination change)
- 目标尺寸变化(object size change)
- 目标动作变化(object motion change,和相机抖动表现形式类似,都是模糊)
- 未退化(non-degraded)。
除此之外,VOT认为序列中的每一帧都需要进行视觉属性的标注,即使是同一序列,不同帧的视觉属性也不同,这么做可以对tracker进行更精准的评价。
(3). 评价系统:在VOT提出之前,比较流行的评价系统是让tracker在序列的第一帧进行初始化,之后让tracker一直跑到最后一帧。然而tracker可能会因为其中一两个因素导致其在开始的某些帧就跟丢(fail),所以最终评价系统只利用了序列的很小一部分,造成浪费。而VOT提出,评价系统应该在tracker跟丢的时候检测到错误(failure),并在failure发生的5帧之后对tracker重新初始化(reinitialize),这样可以充分利用数据集。之所以是5帧而不是立即初始化,是因为failure之后立即初始化很可能再次跟踪失败,又因为视频中的遮挡一般不会超过5帧,所以会有这样的设定。
这是VOT的一个特色机制,即重启(reset/reinitialize)。但重启之后的一部分帧是不能用于评价的,这些帧被称作burn-in period,大量实验结果表明,burn-in period大约为初始化之后(包括第一帧的初始化和所有重启)的10帧。
接下来介绍VOT最重要的两个评价指标:Accuracy和Robustness
Accuracy
Accuracy用来评价tracker跟踪目标的准确度,数值越大,准确度越高。它借用了IoU(Intersection-over-Union,交并比)定义,某序列第t帧的accuracy定义为: \(\phi_t=\dfrac{A_t^G \cap\ A_t^T}{A_t^G \cup\ A_t^T}\) 其中$A_t^G$代表第$t$帧ground truth对应的bounding box,$A_t^T$ 代表第$t$帧tracker预测的bounding box。
更详细一些,定义$\Phi_t(i,k)$为第$i$个tracker在第 $k$ 次重复(repetition,tracker会在一个序列上重复跑多次)中在第 $t$ 帧上的accuracy。设重复次数为$N_{rep}$,所以 第 $t$ 帧上的accuracy定义为: \(\Phi_t(i)=\frac{1}{N_{rep}}\sum_{i=1}^{N_{rep}} \Phi_t(i,k)\) 第$i$个tracker的average accuracy定义为: \(\rho_A(i)=\frac{1}{N_{valid}}\sum_{t=1}^{N_{valid}} \Phi_t(i)\) 其中$N_{valid}$代表有效帧(valid frames)的数量,除了burn-in period之外的帧均为有效帧。
Robustness
Robustness用来评价tracker跟踪目标的稳定性,数值越大,稳定性越差。仿照上面accuracy的定义,我们可以很容易得出robustness的计算公式。定义$F(i,k)$为第$i$个tracker在第$k$次重复中failure的次数。
所以第$i$个tracker的average robustness定义为: \(\rho_R(i)=\frac{1}{N_{rep}}\sum_{k=1}^{N_{rep}} F(i,k)\)
至此,accuracy和robustness的定义已经讲述完毕,接下来按照时间顺序讲述VOT2013到VOT2016期间评价指标的发展历程。
2. VOT2013
(1). VOT数据集的标注(annotation)及构成
给视频序列手工标注ground truth不是一件简单的事,而且很难对标注制定一个统一的标准。一般来说,标注的bounding box中,有超过60%的像素都属于目标,就算符合标准。当然,大多数情况下,这个百分比会比60%高很多。
至于数据集的构成,在本文的第1大节说过,VOT2013中分为六种属性。具有相同属性的序列放在一起称作属性序列(attribute sequence)
(2). 排名机制(ranking-based)
VOT的排名机制也是其特色之一,所谓排名,正如其字面意思,将tracker在不同属性序列上的表现按照accuracy(A)和robustness(R)分别进行排名,再进行平均,得到该tracker的综合排名,依据这个综合排名的数字大小对tracker进行排序得出最后排名。这个排名叫做AR rank。
具体操作为:首先让tracker在同一属性的序列下测试,对得到的数据(average accuracy/average robustness)进行加权平均,每个数据的权重为对应序列的长度,由此得到单个tracker在该属性序列上的数据,然后对不同tracker在该属性序列下进行排名。得到单个tracker在所有属性序列下的排名后,求其平均数(不加权)得到AR rank。
(3). 如何判断两个tracker在实际情况下表现相同/不相同(tracker equivalence)
上文提到,实验数据不等同于实际表现,所以测试平台都想尽力还原真实场景,那么仅仅根据测试数据的大小就评判一个tracker的性能还是不够的,所以VOT提出了equivalent tracker的概念——accuracy和robustness可以利用非参数检验来验证两个tracker之间的评价是否存在显著差异。针对accuracy,应用 Wilcoxon Signed-Rank test;针对robustness,应用Wilcoxon Rank-Sum (MannWhitney U-test)。(由于笔者的数理统计知识有欠缺,这一段不能作出详细的分析,只能根据论文内容进行粗略的总结,待笔者之后补充,读者可以跳过这一段)
2. VOT2014
(1). 评价tracker跟踪速度的指标——EFO
我以前在看一些目标跟踪领域的论文时,有过这样的疑问:每篇文章提出的算法都是在不同硬件条件平台上跑的,编程语言也不尽相同,那么该如何对这些算法进行客观评价?而VOT就给了我一个答案:EFO。
EFO(Equivalent Filter Operations )是VOT2014提出来的一个衡量tracking速度的新单位,在利用vot-toolkit评价tracker之前,先会测量在一个600600的灰度图像上用3030最大值滤波器进行滤波的时间,以此得出一个基准单位,再以这个基础单位衡量tracker的速度,以此减少硬件平台和编程语言等外在因素对tracker速度的影响。
(2). 衡量equivalence的另一种机制——practical difference
VOT2014提出了衡量tracker的另一种机制——practical difference,简单来说,就是不再仅仅依靠显著性差异(statistical difference)。值得一提的是,practical difference只针对accuracy并没有涉及robustness。
在第1大节我们说过accuracy的定义和公式。定义$\phi_t(i)$和$\phi_t(j)$为tracker-i和tracker-j在t帧时的accuracy,$\rho_A(i)$和$\rho_A(j)$是第$i$和第$j$个tracker的average accuracy,前后者之间的关系参考上文。再定义一个阈值$\gamma$(这个$\gamma$值如何取我就不再多说,感兴趣的读者可以去文末参考文献中VOT2014那篇查阅)。如果有: \(|\rho_A(i)-\rho_A(j)|>\gamma\) 则称tracker-i和tracker-j通过测试。
上式还有其他形式:定义$d_t(i,j)=\phi_t(i)-\phi_t(j)$,则上式可以表示为: \(\frac{1}{T}|\sum_{t=1}^T {\frac{d_t(i,j)}{\gamma}}|>1\)
又因为$\gamma$随帧的不同而变化,所以上式又修正为: \(\frac{1}{T}|\sum_{t=1}^T {\frac{d_t(i,j)}{\gamma_t}}|>1\) $\gamma_t$是第t帧对应的阈值。
到此,我们可以得到判断两个tracker表现相同的条件:
- 差异不显著
- 未通过测试
3. VOT2015
(1). 不同于AR rank的评价指标——EAO
VOT2015提出,基于AR rank的评价方式没有充分利用accuracy和robustness的原始数据(raw data),所以创造了一个新的评价指标——EAO(Expected Average Overlap)。正如字面意思,这个评价指标只针对基于overlap定义的accuracy。
EAO的大致思路为:首先将所有序列按照长度分类,令待测tracker在长度为$N_s$的序列上测试,得到每一帧的accuracy $\Phi(t)$。(特别注意,这里和之前定义的accuracy有略微不同,这里只跑一次,即$N_{rep}=1$,所以括号里没有$k$),之后进行平均,得到该序列上的accuracy:$\Phi_{N_s}=\frac{1}{N_s}\sum_{i=1}^{N_s} \Phi(t)$。
长度为$N_s$的序列不止一个,tracker要在这些序列上全跑一遍,再求平均: \(\hat\Phi_{N_s}=\dfrac{1}{N_s}\sum_{i=1}^{N_s}\Phi_{N_s}\) 这样就得到了该tracker在长度$N_s$序列上的EAO值。之后在其他长度的序列上测EAO,就可以得到一条EAO曲线,横坐标为序列长度,纵坐标为EAO值。
另外,如果对不同$N_s$值的$\hat\Phi_{N_s}$再次求平均:设序列长度范围为$[N_{lo},N_{hi}]$,则: \(\hat\Phi=\dfrac{1}{N_{hi}-N_{lo}}\sum_{N_s=N_{lo}}^{N_{hi}}\hat\Phi_{N_s}\)
$\hat\Phi$是一个值,所以将不同tracker的$\hat\Phi$值绘制成一张图就是EAO点图。
(2). AR rank的新表示方法
AR rank在VOT2015有了新的表示方法:
- pooled AR rank:将所有序列的测试结果分别排名,然后再取平均得到平均排名(即跳过attribute sequence);
- attribute normalized AR rank:定义和之前的AR rank相同;
- pooled AR scores:同pooled AR rank,只是不用排名,而是直接采用原始数据;
- attribute normalized AR scores:同attribute normalized AR rank,只是不用排名,而是直接采用原始数据。
但是,这里有一点非常重要,就是关于pooled AR scores和attribute normalized AR scores,只要细心一点的读者看图就能发现一些问题——
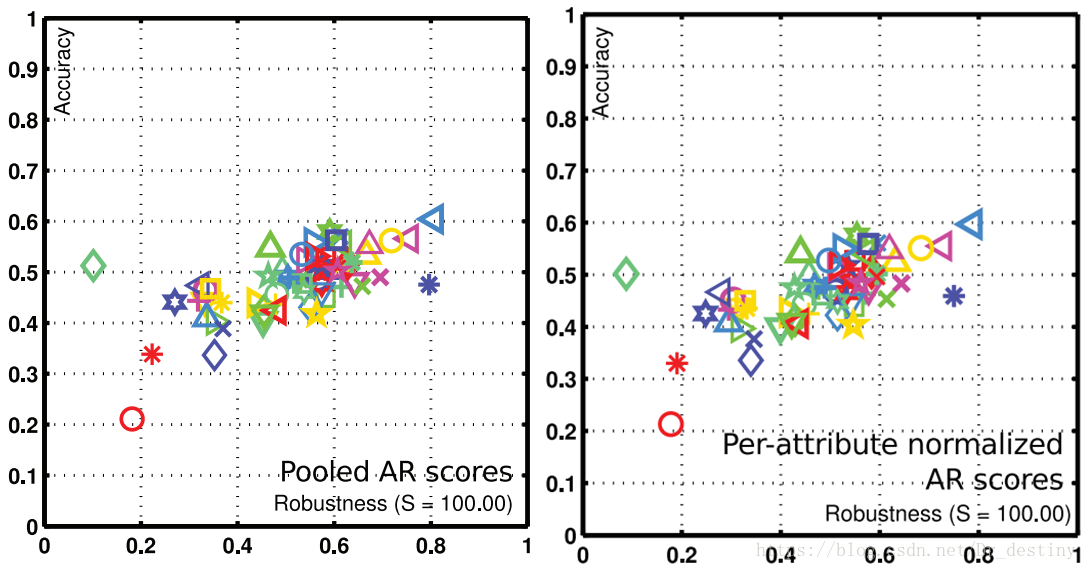
其实这一点在文章Visual object tracking performance measures revisited里有提到过,这里的Robustness是经过改动了的,由以下公式定义: \(R_S = e^{-SM}\) 其中,$R_S$就是重新定义后的Robustness,而$M$其实是Robustness的原始数据,$S$是人为定义的一个数,在图中设为100(这也是为什么单目标跟踪的论文里所有AR Scores的图中在横坐标Robustness后面都有一个括号标明$S$值是多少)。因为$R_S = e^{-SM}$是关于$M$的减函数,所以$R_S$越大,就表明该tracker越稳健,更加直观明了。
重新定义的Robustness还可以叫做reliability,可以解释为“上一次跟踪失败后能够持续跟踪$S$帧的概率”(文中原话)。 —
4. VOT2016
VOT2016相比VOT2015变化不大,评价指标上,从OTB(另外一个测试平台,开头提到过)引入了AO(Average Overlap),与EAO的不同之处也仅在于AO没有VOT的重启机制。
到此,整篇文章的正文部分已经结束了。这两篇文章总结了我这段时间对VOT的认识与实践,也算是对毕设中期的一个见证。关于文中某些部分理论讲解不清楚的问题,由于笔者当前知识水平还不够,不足以作出清晰的解释,待笔者学习一段时间后,会对这些部分进行补充,请见谅。
参考文献
[1] Kristan M, Matas J, Leonardis A, et al. A novel performance evaluation methodology for single-target trackers[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 38(11): 2137-2155.
[2] Kristan M, Matas J, Leonardis A, et al. The Visual Object Tracking VOT2013 challenge results[J].Proceedings of the IEEE International Conference on Computer Vision workshops. 2013:98-111.
[3] Kristan M, Pflugfelder R, Leonardis A, et al. The Visual Object Tracking VOT2014 challenge results[J]. COMPUTER VISION - ECCV 2016 WORKSHOPS, PT II, 2014, 8926:191-217.
[4] Kristan M, Pflugfelder R, Matas J, et al. The Visual Object Tracking VOT2015 Challenge Results[C]// IEEE International Conference on Computer Vision Workshop. IEEE, 2016:564-586.
[5] Kristan M, Leonardis A, Matas J, et al. The Visual Object Tracking VOT2016 Challenge Results[J]. COMPUTER VISION - ECCV 2016 WORKSHOPS, PT II, 2016, 8926:191-217.
[6] Čehovin L, Leonardis A, Kristan M. Visual object tracking performance measures revisited[J]. IEEE Transactions on Image Processing, 2016, 25(3): 1261-1274.